
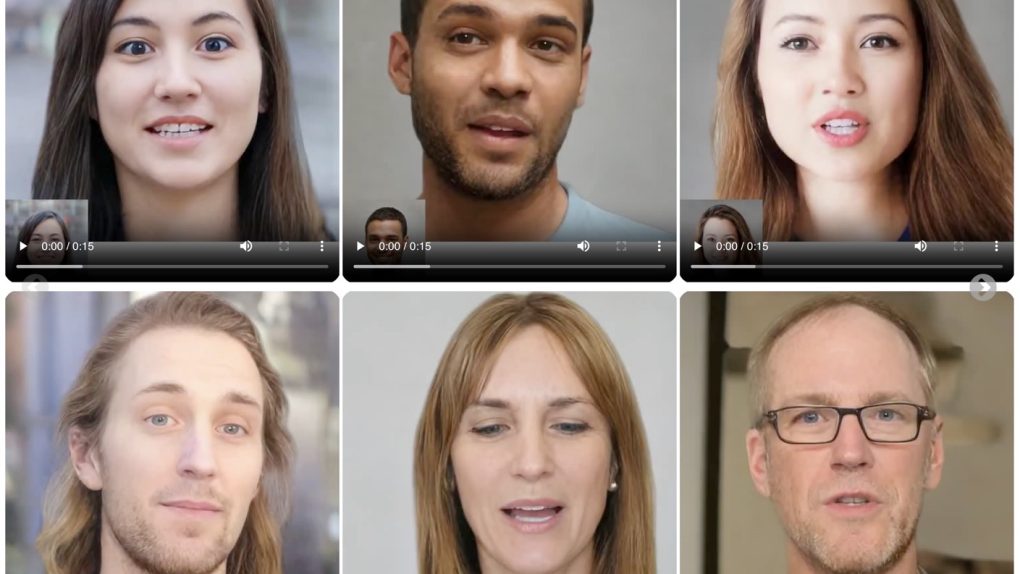
The time of AI assistants is ever closer: interfacing with digital faces and avatars is rapidly becoming an integral part of our daily lives. How far can these digital faces go in replicating the realism of a real person? Very far away, judging by VASA-1, the innovative artificial intelligence model just developed by Microsoft Research. Here you can find the paper.
VASA-1 can generate ultra-realistic videos of talking faces in real time from a single image and an audio file. It will push the boundaries of what is possible in creating digital avatars, with applications ranging from video calls to entertainment content to improving accessibility for people with hearing impairments.

VASA-1, unprecedented realism
What makes VASA-1 truly revolutionary is the level of realism it is capable of achieving. The videos generated by this AI model are virtually indistinguishable from those of real people.
This is made possible by a series of innovative features. First of all, VASA-1 offers perfect synchronization between lip movements and audio. Regardless of the language or the presence of background noise, the avatar's lips move in perfect synchrony with the words spoken, creating an effect of surprising realism.
Furthermore, VASA-1 is capable of capturing and reproducing a wide range of facial expressions, from the subtlest nuances to the most marked emotions. This adds an extra level of depth and authenticity to the generated avatars and the “digital people".
Finally, head movements are generated in a natural and fluid way, contributing to the impression of being in front of a real person and not a static image.

Real-time generation and high quality
I find the VASA-1's ability to generate these ultra-realistic videos in real time impressive. It currently has a resolution of 512x512 pixels and a speed of up to 40 frames per second, but they are live talking avatars, without delays or interruptions.
This paves the way for a number of innovative applications. For example, VASA-1 could be used to create personalized avatars for video calls, making virtual interactions more engaging and realistic. It could also be used to generate interactive characters in video games or to create educational and entertaining video content with virtual presenters.
Towards greater accessibility
One of the most interesting potential applications of VASA-1 involves accessibility. By generating videos of talking faces from an audio file, this AI model could be used to create accessible versions of video content for people with hearing disabilities.
Imagine being able to watch a speech or lecture with a speaker avatar clearly articulating the words in sync with the audio. This could make the contents much more usable for those with hearing difficulties, opening up new possibilities for learning and participation.
The future of VASA-1 and virtual communication
Microsoft researchers are not satisfied and are already working to further improve the performance of VASA-1. In the future, we can expect talking avatars of even higher quality, even smoother and with higher resolutions. Not to mention times and costs for films and animations: they will be totally changed.
Those of you who remember the pioneering TV series "Max headroom“? There a real journalist was "resurrected" as a virtual avatar. A visionary series, 30 years ago, which will soon be totally outclassed by the facts. As VASA-1 and similar technologies advance, the line between virtual communication and face-to-face interaction may become increasingly blurred.
Of course, this perspective also raises ethical and social questions. It will be important to develop guidelines and regulations to ensure responsible and transparent use of these technologies, protecting privacy and preventing potential abuses such as the creation of deepfakes.
That said, the potential benefits of models like VASA-1 are enormous.
From more engaging communication to enhanced learning, from more interactive entertainment to greater accessibility, the applications are vast and promising.
VASA-1 offers us a fascinating glimpse into a future in which virtual communication will be increasingly indistinguishable from face-to-face communication. It's a future where ultra-realistic avatars can convey not only words, but also emotions, expressions and presence. A future where physical distance will be less of a barrier and where accessibility to content will be greatly improved.
I'm really curious to see how VASA-1 (and its successors) will transform the way we communicate, learn and entertain ourselves in the years to come. The digital face revolution has just begun, and the future seems more realistic than ever.

